DeepSeek V4 正式发布:AI-AutoShot 同步支持最新模型
🚀 重磅来了:DeepSeek V4 系列已经正式发布
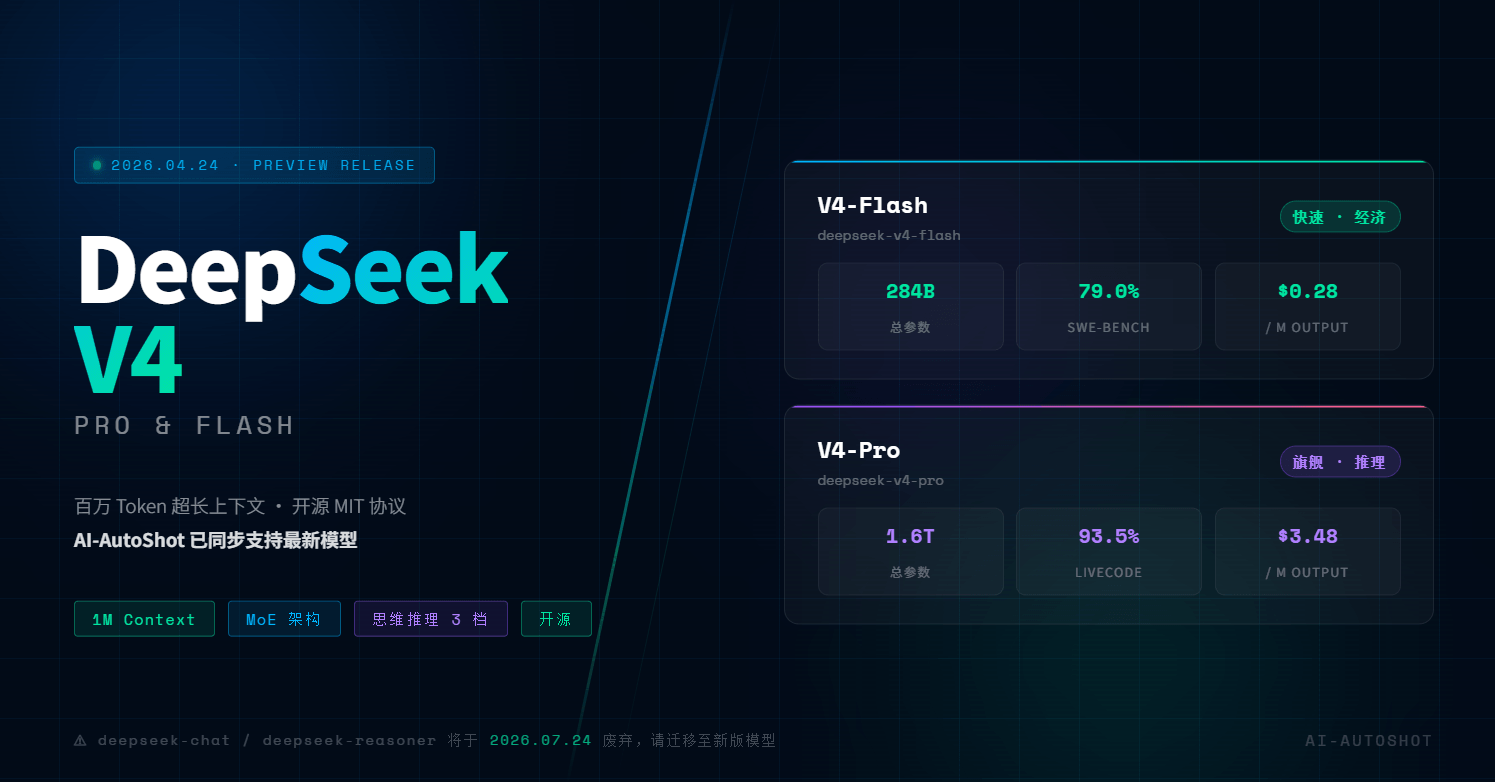
期待已久的 DeepSeek 正式推出了 V4 系列的两款预览版模型——DeepSeek-V4-Flash 与 DeepSeek-V4-Pro,距离上次"震动全球科技圈"的 R1 发布已有一年时间。
两款模型均以 MIT 开源协议发布于 Hugging Face,支持高达 100 万 Token 的超长上下文,同时兼容 OpenAI ChatCompletions 与 Anthropic API 格式,开箱即用。
⚠️ 官方通知:原有的 deepseek-chat 与 deepseek-reasoner 接口将于 2026 年 7 月 24 日弃用。
📦 两款模型一览
| DeepSeek-V4-Flash | DeepSeek-V4-Pro | |
|---|---|---|
| API 模型 ID | deepseek-v4-flash |
deepseek-v4-pro |
| 总参数量 | 284B | 1.6T |
| 激活参数量 | 13B / Token | 49B / Token |
| 上下文窗口 | 100 万 Token | 100 万 Token |
| 架构 | MoE(混合专家) | MoE(混合专家) |
| API 输入价格 | $0.14 / M tokens | $1.74 / M tokens |
| API 输出价格 | $0.28 / M tokens | $3.48 / M tokens |
| 推理模式 | 支持(3 档强度) | 支持(3 档强度) |
| 定位 | 快速 · 经济 · 日常首选 | 旗舰 · 强推理 · 复杂任务 |
🔬 DeepSeek-V4-Flash:小体格,大能耐
V4-Flash 以 284B 总参数 / 13B 激活参数的轻量架构,打出了令人意外的高分——
- SWE-bench Verified(代码能力):79.0%,与旗舰版 V4-Pro(80.6%)仅差 1.6 个百分点
- LiveCodeBench(实时编程):91.6%,比 V4-Pro 的 93.5% 仅低 2 个点
- BenchLM 编程类排名:全球第 11(115 个模型中)
- 价格仅为 V4-Pro 的 1/12.4,是目前小模型中价格最低的选项之一
Flash 的弱项在于复杂多步骤工具调用(Terminal-Bench 2.0:56.9% vs Pro 的 67.9%)和事实性知识召回(SimpleQA-Verified:34.1% vs Pro 的 57.9%)。日常写作、代码辅助、创意生成等场景,Flash 是妥妥的性价比之王。
🏆 DeepSeek-V4-Pro:开源世界新王者
V4-Pro 以 1.6T 总参数刷新了开源模型的规模记录,超越此前最大的 Kimi K2.6(1.1T),并在多个关键榜单上挑战闭源顶尖模型——
编程能力:局部超越 Claude
| 基准测试 | DeepSeek-V4-Pro | Claude Opus 4.6 |
|---|---|---|
| Terminal-Bench 2.0 | 67.9% ✅ | 65.4% |
| LiveCodeBench | 93.5% ✅ | 88.8% |
| SWE-bench Verified | 80.6% | 80.8% |
| Codeforces Rating | 3206 ✅ | 未报告 |
数学与推理:接近但未超越顶线
| 基准测试 | DeepSeek-V4-Pro | 对比 |
|---|---|---|
| HMMT 2026 数学竞赛 | 95.2% | Claude 96.2% / GPT-5.4 97.7% |
| HLE(跨领域专家推理) | 37.7% | Gemini-3.1-Pro 44.4% |
| SimpleQA-Verified(事实召回) | 57.9% | Gemini 75.6% |
结论:V4-Pro 在代码生成领域已达到甚至部分超越闭源前沿模型水平,但在复杂跨领域推理和事实性知识上,与 Gemini-3.1-Pro 仍有差距。以 $3.48/M 输出 Token 对比 Claude 的 $25/M,性价比优势高达 7 倍。
⚙️ 核心架构升级
DeepSeek V4 系列带来了两项重要的底层创新:
① 混合注意力机制(CSA + HCA) 结合压缩稀疏注意力(CSA)与重度压缩注意力(HCA),在 100 万 Token 超长上下文下,V4-Pro 的单 Token 推理计算量仅为 V3.2 的 27%,KV 缓存仅需 10%,长文档处理效率大幅提升。
② 流形约束超级连接(mHC) 增强残差连接,改善深层网络的信号传播稳定性,提升模型在复杂任务上的整体表现。
🎛️ 三档推理模式
两款模型均支持动态调节推理强度,适配不同场景需求:
| 模式 | 适用场景 |
|---|---|
| Non-Thinking(快速) | 日常问答、创意写作、简单代码 |
| Thinking(标准推理) | 中等复杂度编程、数学题、分析任务 |
| Think Max(最大推理) | 竞赛级数学、复杂代码架构、深度分析 |
Think Max 模式建议将上下文窗口设置为至少 384K Token。
🔄 AI-AutoShot 已同步更新
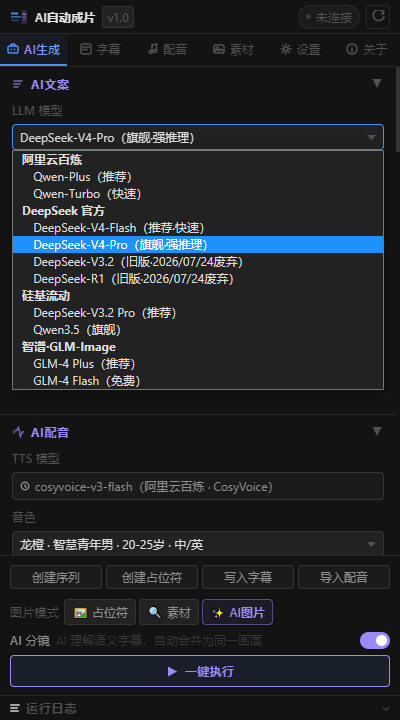
本次 AI-AutoShot 插件已第一时间跟进 DeepSeek 官方 API 变更:
- ✅ 新增
deepseek-v4-flash(DeepSeek-V4-Flash · 推荐 · 快速) - ✅ 新增
deepseek-v4-pro(DeepSeek-V4-Pro · 旗舰 · 强推理) - ⚠️ 保留旧版
deepseek-chat/deepseek-reasoner,标注废弃时间,供过渡使用 - 🔁 默认模型已切换为
deepseek-v4-flash
如何选择?
- 📸 日常 AI 出图描述 / 批处理场景 → 选
deepseek-v4-flash,速度快、成本低 - 🧠 需要更精准的创意描述 / 复杂提示词生成 → 选
deepseek-v4-pro,质量更稳定